Loading... # kafka如何保证不重复消费又不丢失数据 > 参考文章:[kafka 如何保证不重复消费又不丢失数据?](https://www.zhihu.com/question/483747691/answer/2392949203) ## kafka消息丢失 ### 发送时丢失 用Producer发消息至Broker的时候,有可能会丢消息 带有callBack的api进行发送,如果发送成功回调方法会收到成功,如果失败,在业务上做重试。 设置retries参数,发送失败自动重试 ### Broker收到消息后丢失 broker收到消息,还没同步给其他broker就挂掉了。kafka默认是异步刷盘,刷盘之前数据是存储在OS Cache中,如果还没来得及刷盘就挂了,数据同样会丢失。 设置`replication.factor`副本数量,保证数据冗余。 设置`acks=ALL`所有broker同步完成,才给生产者返回ack。 kafka没有同步刷盘策略,但是可以通过参数配置实现,只是会影响性能。 ``` # 当达到下面的消息数量时,会将数据flush到日志文件中。默认10000 #log.flush.interval.messages=10000 # 当达到下面的时间(ms)时,执行一次强制的flush操作。interval.ms和interval.messages无论哪个达到,都会flush。默认3000ms #log.flush.interval.ms=1000 # 检查是否需要将日志flush的时间间隔 log.flush.scheduler.interval.ms = 3000 ``` ### 消费时数据丢失 要保证消费时数据不丢失,首先要设置手动提交offset。 1. Kafka拉取消息(一次批量拉取500条,这里主要看配置)时 2. 为每条拉取的消息分配一个msgId(递增) 3. 将msgId存入内存队列(sortSet)中 4. 使用Map存储msgId与msg(有offset相关的信息)的映射关系 5. 当业务处理完消息后,ack时,获取当前处理的消息msgId,然后从sortSet删除该msgId(此时代表已经处理过了) 6. 接着与sortSet队列的首部第一个Id比较(其实就是最小的msgId),如果当前msgId<=sort Set第一个ID,则提交当前offset 7. 系统即便挂了,在下次重启时就会从sortSet队首的消息开始拉取,实现至少处理一次语义 8. 会有少量的消息重复,但只要下游做好幂等就OK了。 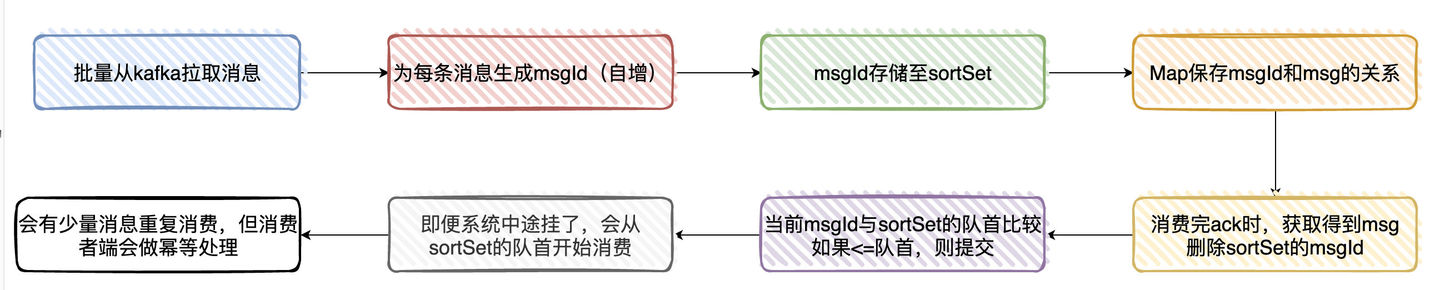 ## kafka幂等性 以处理订单为例 1. 幂等Key我们由订单编号+订单状态所组成(一笔订单的状态只会处理一次) 2. 在处理之前,我们首先会去查Redis是否存在该Key,如果存在,则说明我们已经处理过了,直接丢掉 3. 如果Redis没处理过,则继续往下处理,最终的逻辑是将处理过的数据插入到业务DB上,再到最后把幂等Key插入到Redis上 单纯通过Redis是无法保证幂等的 所以,Redis其实只是一个「前置」处理,最终的幂等性是依赖数据库的唯一Key来保证的(唯一Key实际上也是订单编号+状态) 总的来说,就是通过Redis做前置处理,DB唯一索引做最终保证来实现幂等性的 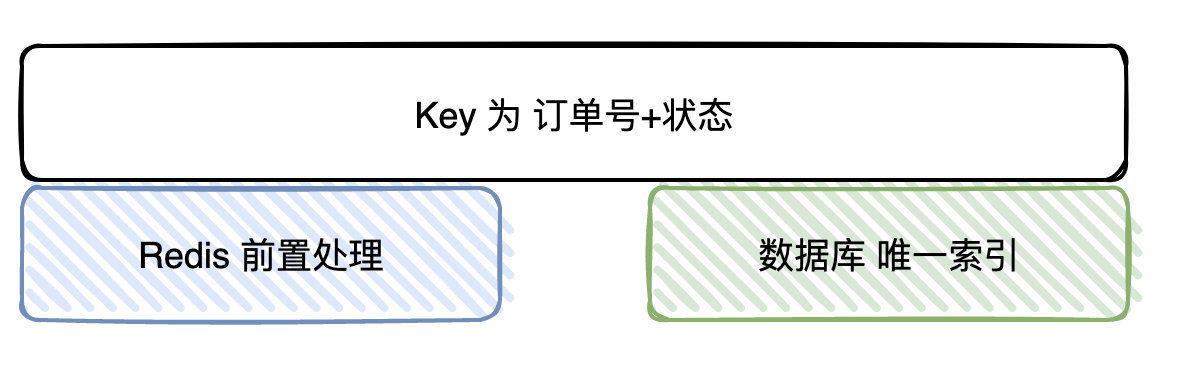 ## 顺序消费 以订单状态消费为例: 订单的状态比如有 支付、确认收货、完成等等,而订单下还有计费、退款的消息报 理论上来说,支付的消息报肯定要比退款消息报先到,但程序处理的过程中却不一定。 但在广告场景下不是「强顺序」的,只要保证最终一致性就好了。 所以我们这边处理「乱序」消息的实现是这样的: 1. 宽表:将每一个订单状态,单独分出一个或多个独立的字段。消息来时只更新对应的字段就好,消息只会存在短暂的状态不一致问题,但是状态最终是一致的 2. 消息补偿机制:另一个进行消费相同topic的数据,消息落盘,延迟处理。将消息与DB进行对比,如果发现数据不一致,再重新发送消息至主进程处理 3. 还有部分场景,可能我们只需要把相同userId/orderId发送到相同的partition(因为一个partition由一个Consumer消费),就能解决大部分消费顺序的问题。  Last modification:July 17th, 2022 at 09:21 pm © 允许规范转载
哈哈哈,写的太好了https://www.lawjida.com/